
ZMonster's AI Notes(Alpha) #1
2023-12-19目录
- 术语
- 论文
- Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning
- A Study on the Calibration of In-context Learning
- Comparable Demonstrations are Important in In-Context Learning: A Novel Perspective on Demonstration Selection
- GPT-RE: In-context Learning for Relation Extraction using Large Language Models
- 其他一些看过了觉得没什么收获的论文
- 实践
本系列内容模式的最终形态尚不确定,可能会根据个人精力、兴趣及阅读反馈做调整。
术语
简单介绍下我上一周中新了解到的 AI 领域的一些术语,但不做深入探究。
模型编辑(model editing)
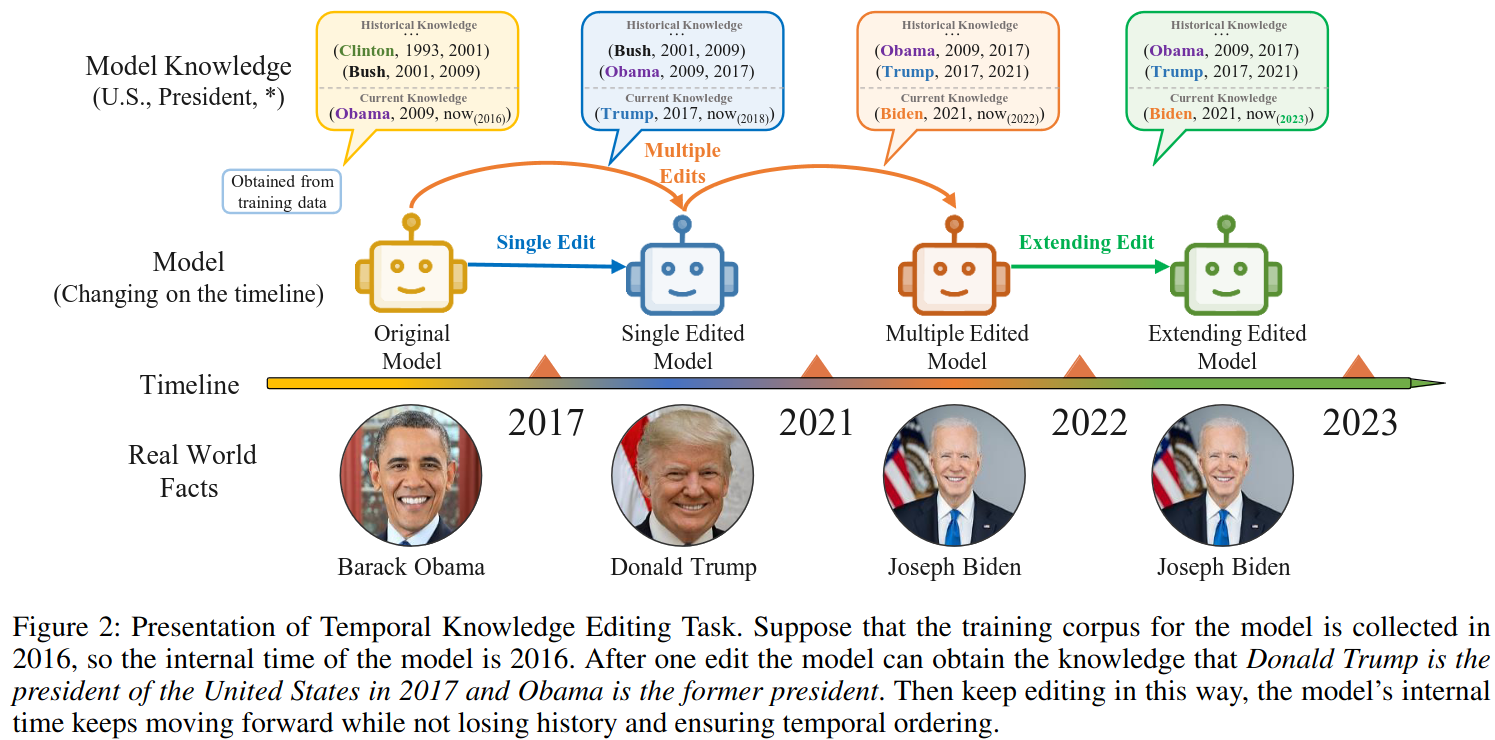
指对已有的神经网络模型进行局部修改,使得模型能在单个或者少量数据上的预测行为发生变化但又不影响这些数据之外其他数据及任务的表现,以应对少量 badcase 修复、知识随时间更新等场景。
模型编辑可以最粗暴地通过对预训练模型进行直接微调来做到,但可能因为数据量太少而效果不佳,除此以外还有一些方法会尝试定位到具体的一些神经元做局部参数修改。广义上来说,通过外部知识进行增强(比如将正确的或者新知识后填充到 Prompt 里)、在主模型外附加针对性的额外参数(这些额外参数可以比较少然后用对应的少量数据训练)也算是模型编辑。
模型编辑和知识编辑(knowledge editing)在概念上有较大的重叠。
对齐税(alignment tax)
又称对齐成本(alignment cost)、安全税(safety tax),指对 AI 系统(目前来说,主要是大语言模型)进行对齐的过程中产生的额外成本,大致将其分成三类,分别是:由于对齐而导致的性能/效果的退化、为了对齐而增加的额外开发/计算资源、为了对齐而增加的额外时间。
校准(calibration)
指模型的预测概率与实际概率一致的程度,如果两者完全一致就可以说模型是「被校准的」。从实用角度来说,一个被校准的模型,其预测结果的置信度会是真正可信的 —— 做过机器学习业务的人应该都有这个感觉,很多时候模型输出的置信度并不能真的帮助我们判断结果是否可靠,比如说一个错误的预测其置信度也高达 80% 甚至 90% 之类的。一些研究表明,一些情况下预训练模型随着模型尺寸增大其校准程度会降低、预测概率的分布会高度集中在窄小的区间(虽然与此同时其准确率也在提高),对模型进行微调也有类似的现象。关于校准的研究致力于评估模型的校准程度以及研究提高模型校准程度的方法。期望校准误差(Expected Calibration Error, ECE)是一个较通用的评估模型偏离期望校准程度的指标。
论文
简单讲一下我上一周中重点读过的一些论文及我个人的相关看法。
由于 EMNLP2023 会议上有一篇关于 In-Context Learning 的论文获得了最佳论文,所以上一周重点读了下 In-Context Learning 相关的论文。In-Context Learning 是指使用大语言模型(不过现在在多模态模型中也看到了使用 In-Context Learning)时,在输入中添加少量的标注过的任务数据来(简单起见,后面我一律称之为「示例」)提高实际预测效果的方法,目前为止对 In-Context Learning 的分析发现了很多问题,比如模型对这些示例的选择甚至排序都很敏感,对 In-Context Learning 的工作原理也还不是特别清楚。
Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning
EMNLP2023 的最佳论文之一。
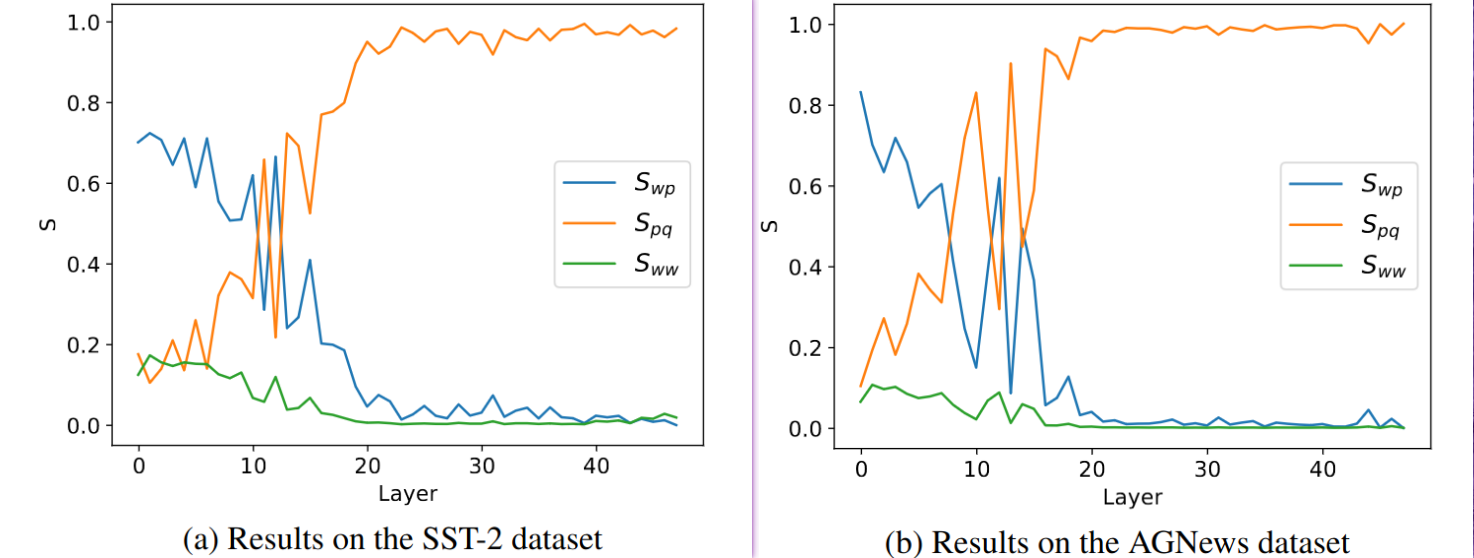
通过逐层计算的基于 attention 权重矩阵的信息流动显著性分数考察了使用 In-Context Learning 时的三个信息流 —— 从示例中文本到示例中标签词的信息流(wp)、从示例中标签词到预测目标位置的信息流(pq)、输入中任意两个词的信息流(ww),发现第一个信息流的显著性在浅层网络中很高并且随层数增加而迅速衰减,第二个信息流则在浅层时不显著但随着在更深层中迅速变得显著,如下图所示:
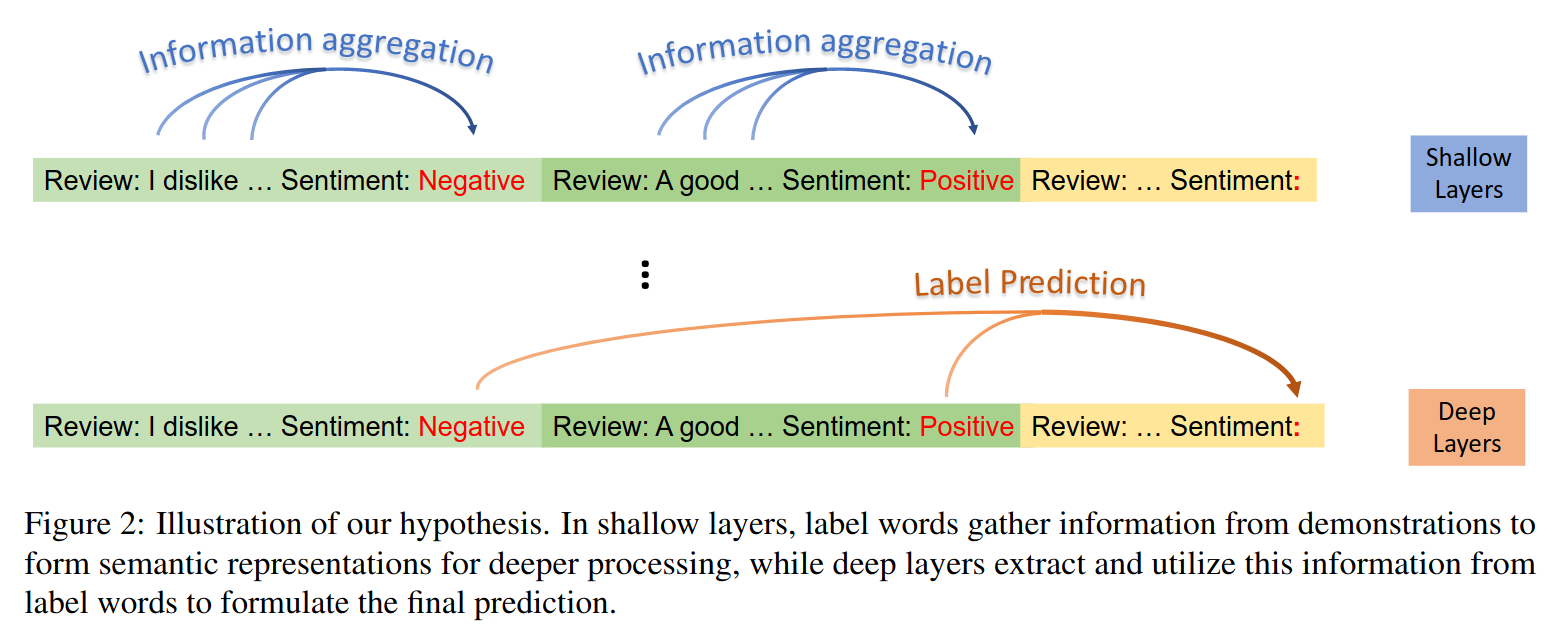
根据上述观察,作者对 In-Context Learning 的工作机制提出了两个假设:
- 在浅层中,标签词从示例样本中聚合信息,形成后续计算的语义表示
- 在深层中,模型通过提取标签词的信息(就是假设 1 中的语义表示)进行预测
这两个假设的可视化地描述的话是下图这个样子:
对第一个假设的验证是通过对不同层不同位置的信息流阻断(通过将对应位置的 attention 置为 0)后观察模型效果变化来完成的,如下图所示:
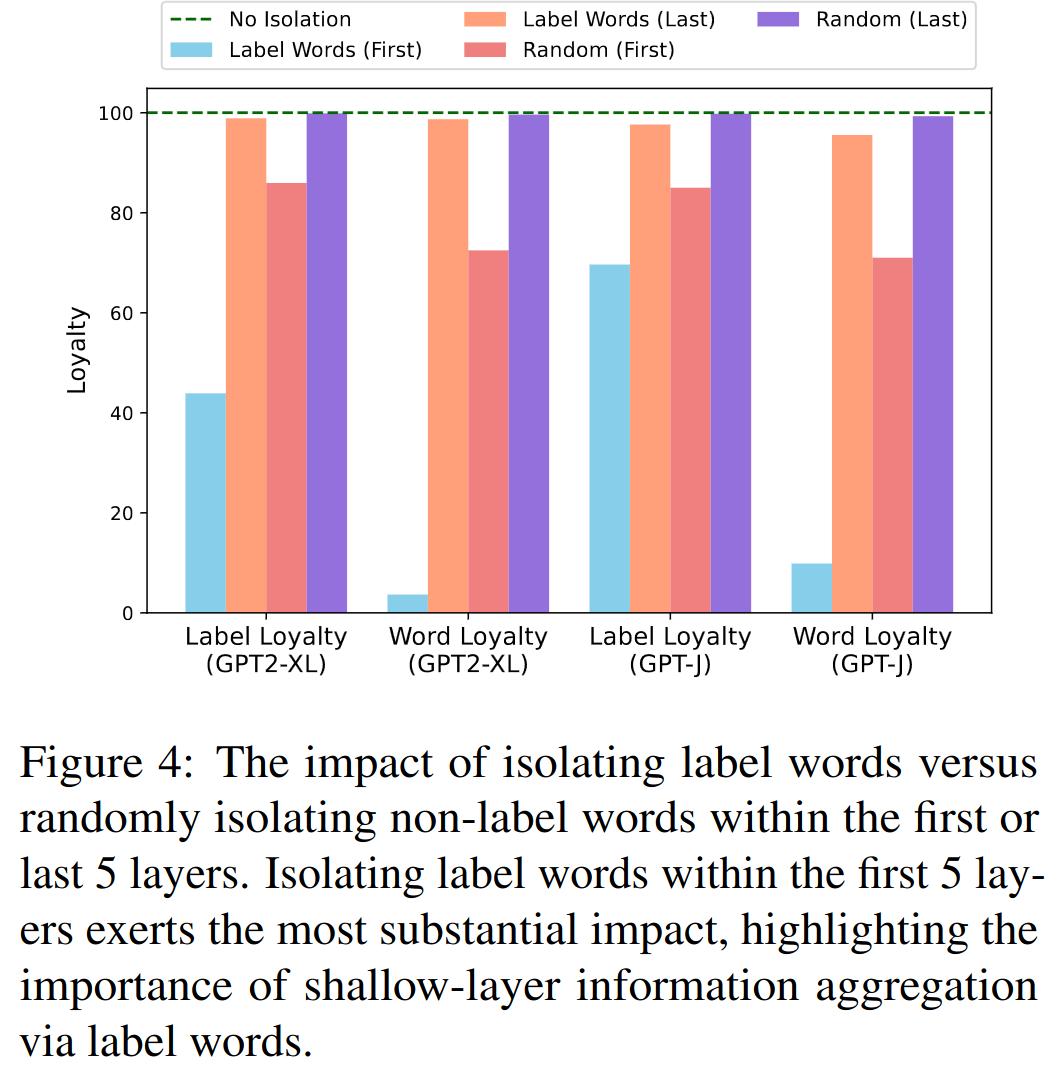
可以看到
- 同样在前 5 层进行阻断时,阻断流向标签词的信息流带来的模型效果损失远远比阻断流向非标签词的大;
- 同样阻断流向标签词的信息流时,在前 5 层进行阻断带来的模型效果损失远远比后五层大,事实上,在后五层对流向标签词的信息流进行阻断时,模型的效果损失非常小
对第二个假设是通过直接考察输出位置对标签词处的 attention 权重、将权重最大的标签词作为预测结果,然后与正确的结果进行对比,计算 AUC-ROC 分数考察两者之间的相关性,如下图所示,可以看到这个相关性在浅层时很不明显但在深层时就很明显了。
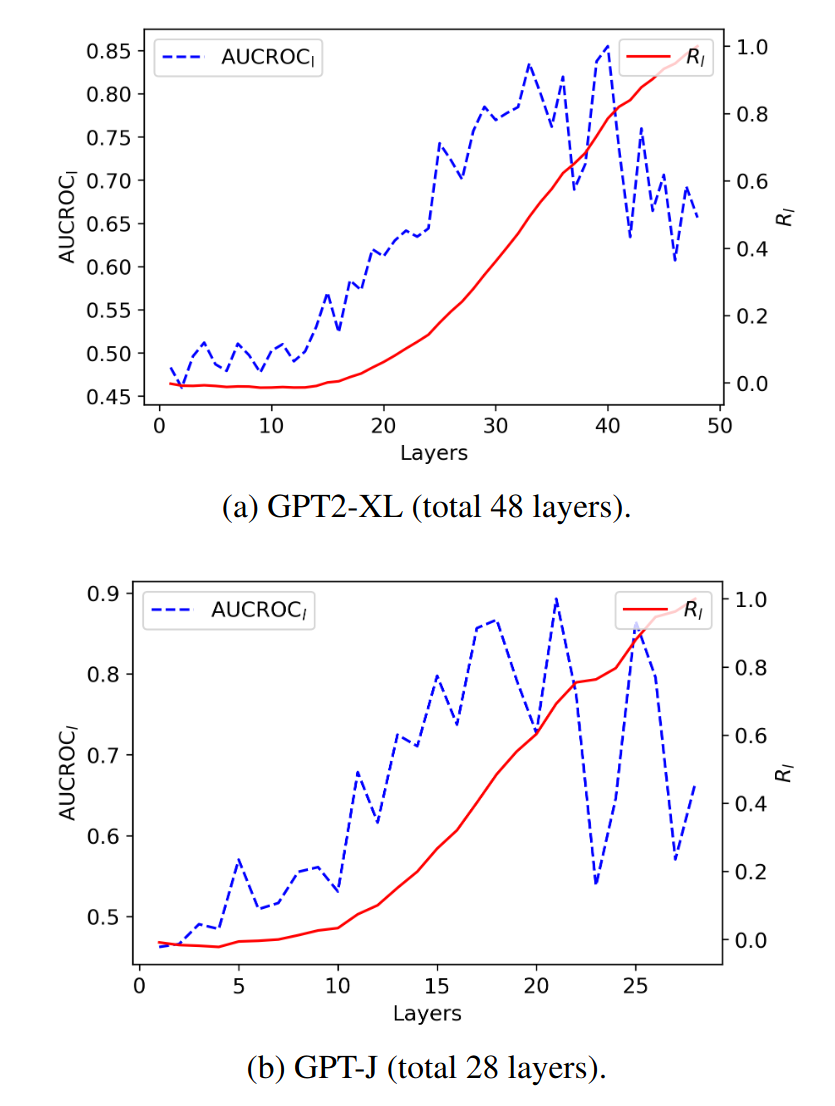
基于这篇论文的假设,作者进而提出了三个对该现象的利用方法
- Anchor Re-weighting: 我理解就是把之前直接用目标位置对标签词的 attention 值来预测类别的方法,形式化后发现和逻辑回归很像,然后逻辑回归会有一个偏置项嘛,所以作者也在这个形式上加了一个偏执项来和逻辑回归对齐(是一种假设模型本身存在 bias 的意思?),然后根据这个形式化假设去学习到这个偏执项里的参数,最后用来调整目标位置在每个标签词上的 attention 值。
- Anchor-Only Context Compression: 大概意思是,预先把示例的 hidden state 算好,然后有真实的任务输入进来的时候,把每一层标签词位置的 hidden state 拿出来拼接起来放到(处理真实任务输入的这个)模型的每一层最前面,这样实际预测的时候就示例中的所有文本就不再需要参与计算了,推理过程就能加速了。
- Anchor Distances for Error Diagnosis: 通过对比示例中标签词的 attention 相关的表示(论文里有一套稍微复杂点的计算过程,暂时没去细看)然后计算不同标签词表示之间的相似度,理想情况下不同标签词的相似度应该较低,当预测结果有错误时可能就有不同的标签词因为 In-Context Learning 而产生了相似的表示,这样通过分析不同标签词之间的混淆情况就能把错误的原因找出来,或许也能去针对性地做调整 —— 比如说把有混淆的那个标签词的文本换成别的?
A Study on the Calibration of In-context Learning
挺有意思的,考察了 LLM 使用 In-Context Learning 时的校准性
- 以 LLaMA 及其微调版本(Vicuna、Alpaca、LLaMA2-Chat)过的模型为研究对象发现微调过后准确度越好的校准性越差
- 使用 4 个示例时,随着模型尺寸的增大,模型的准确度在变高,但同时校准性在变差,模型对自己的预测结果越发自信(对正确的预测和错误的预测都是如此)
- 从不使用示例到只是使用 1 个示例,模型的表现会发生剧烈的变化,当只是增加使用的示例时这种变化就相对平滑了,总体上而言,随着示例数量的增加,模型的准确度会提升,同时也对预测结果越发自信
- 已知常用的通用校准方法(温度缩放/标签平滑)在 In-Context Learning 中效果有限
Comparable Demonstrations are Important in In-Context Learning: A Novel Perspective on Demonstration Selection
这篇论文指出在 ICL 里 context 长度有限的时候示例有限很容易表现出 demenstrations bias,然后提出了 comparable demenstrations 这个概念。
文中所谓 demenstration bias 是说因为示例数量太少,导致他们可以被划分到不唯一的多个任务空间里去,进而影响结果,比如说下面这样两个用于情感分类的示例,不看标签的话两个示例的对比差异不够明显,可以用在情感分类里,也可以用到电影类型分类任务里:
Obviously, Titanic is a well-made romantic film. -> positive Damn, it's a waste of time watching this cartoon! -> negative
在这个想法的基础上,认为 In-Context Learning 里的示例之间的差异应该尽量地凸显在当前这个任务空间下的差异,比如说对给定的示例通过修改其中的少数字词使其标签翻转(比如对情感分析来说,从 positive 变成 negative)得到的新示例和原来的就能构成所谓的可比较示例(comparable demenstrations)。
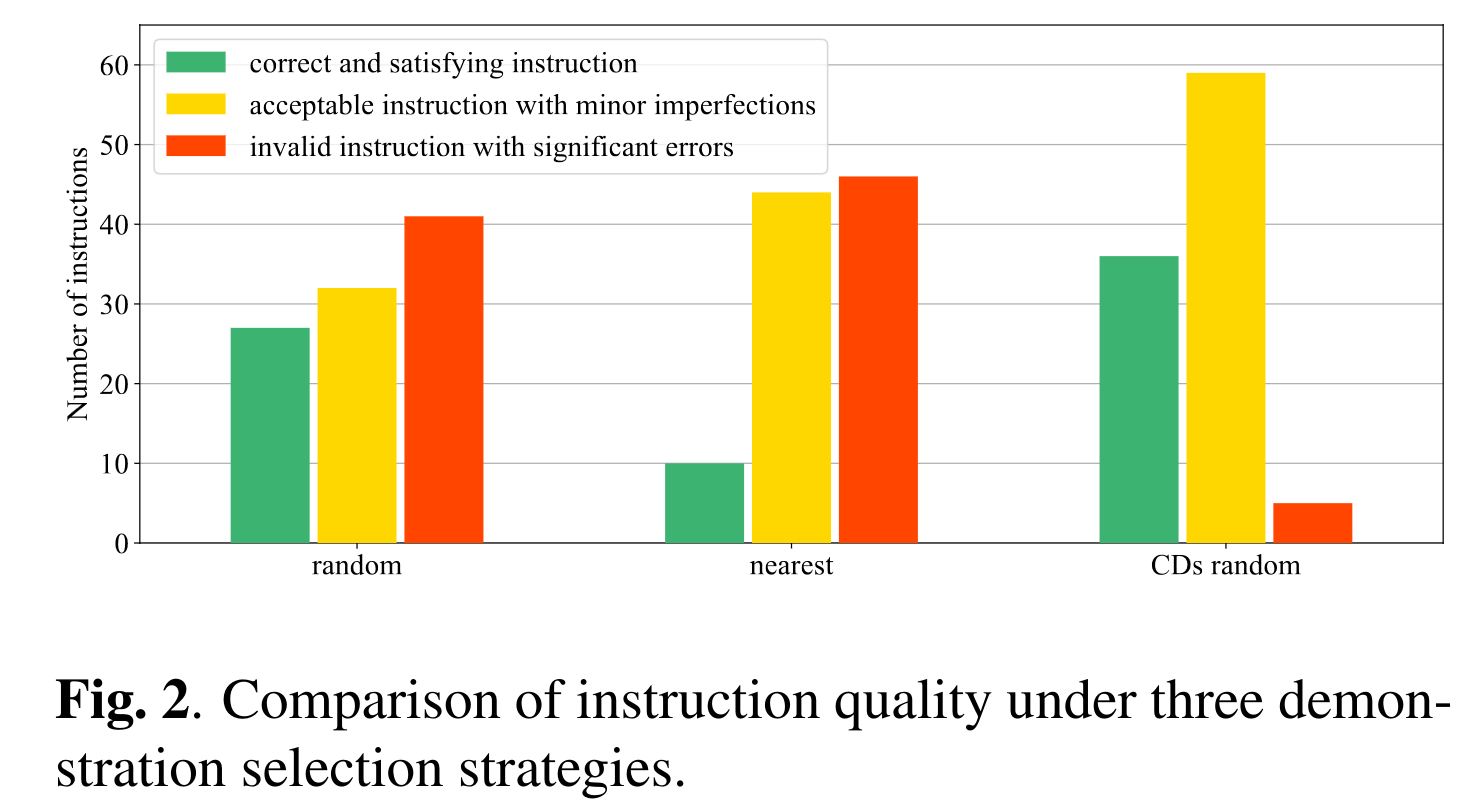
通过给定随机选择的示例、相近的示例、可比较示例然后让 gpt-3.5-turbo 生成 instruction 看 instruction 的正确与否及程度,确认了 demonstration bias 的存在。不过论文自己没有提出具体的可比较示例构建或者搜索方法,直接用了另外一篇相关论文里的数据。
GPT-RE: In-context Learning for Relation Extraction using Large Language Models
这篇论文将 In-Context Learning 应用于关系抽取里,对 In-Context Leanring 本身的研究并没有什么特别的贡献,不过里面有一个有价值的小点,那就是它使用示例时是从标注数据中检索的 —— 之前有工作证明使用与实际任务输入语义相似的示例会提高效果 —— 然后发现在关系抽取任务里用句子 embedding 去检索选择示例带来的收益比想的要小,原因是句子整体语义接近的示例,其中未必会包含和任务实际输入相关的实体、关系,然后通过下面两个方法来改善了结果:
- 一个是在索引示例数据以及检索时,都改写文本,使其更加着重表达实体以及关系,比如说把「He has a sister Lisa.」改写成「The relation between ‘He’ and ‘Lisa’ in the context: He has a sister Lisa.」
- 另外一个是直接用训练好的关系抽取模型(比如 BERT 之类的)来获得句子中关系的表示,比如说用 BERT 里两个实体词对应 hidden state 的拼接
不管是大模型还是 In-Context Learning 还是 Chain-of-Thoughts 之类的看起来很先进的技术,用到具体业务的时候都可以思考一下是不是可以把其中的一些细节根据业务进行适当的调整。
其他一些看过了觉得没什么收获的论文
Active Learning Principles for In-Context Learning with Large Language Models
相关工作部分引用得很全面,我从里面找了一些 In-Context Learning 的论文补充到 Zotero 里。
不过除了引用完善外就没啥新意了,所谓主动学习其实就是通过一些自动化或者半自动化手法(往往让现有模型参与其中)采样高质量数据来降低标注成本然后进一步改进模型如此迭代的做法,在这篇论文里其实讲的就是几种不同的示例采样方法的对比,甚至没有去训练模型,强行和主动学习挂钩,自己也没有提出任何一个新的示例采样方法。
做了几个对比实验得到一些结论
- 按照相似性方法采样得到的效果最好,通过对比(选择最不相似的示例)从反面也论证了这一点,这个反面论证挺有意思
- 在分类任务中,按多样性采样(聚类后从不同簇中选一些示例)的效果仅次于按相似性
- 示例的真实标签是很重要的,和《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》这篇论文中的观察不一致
- 在用不确定性(熵、困惑度)采样时,更小模型(gpt2/gpt2-medium/gpt2-large)似乎需要熵更小的示例效果才能更好,但更大的模型(gpt-neox)似乎开始从高熵的示例中获益
除了第 4 点,其他都有更好的论文提出过了 —— 即使是第 4 点我怀疑也有别的论文提过了。
OverPrompt: Enhancing ChatGPT through Efficient In-Context Learning
就是把分类任务的多个输入放到一个 prompt 里去让直接一次性产生多个输出,以减少计算消耗,同时说还观察到一点点效果的改善,没啥意思。
In-Context Learning for Text Classification with Many Labels
扫了眼感觉没有带来什么新的认知,所谓的标签数量多也没有触及什么真正的困难,没啥意思。
In-Context Learning Dynamics with Random Binary Sequences
搞什么二进制序列预测,通过这个小众任务来将 In-Context Learning 当作贝叶斯模型选择、program induction(我不知道该咋翻译,感觉是认知科学、心理学方面的概念)来去分析,看作者也都是什么心理学、脑科学之类的背景,看着很费劲和我们常关注的点很不一样,所以就没有去看了。
In-Context Learning Functions with Varying Number of Minima
用在数学上的,用来逼近一个有多个极小值的函数之类的,很小众的场景,没什么兴趣。
实践
讲一下我上一周中进行的 AI 方面的实践,可能包括:AI 相关产品或工具的使用,AI 方向的开发实践。
Google Gemini API
12 月 13 日 Google 向开发者开放了 Gemini API,只要有 Google 账户且 QPM 在 60 及以下就可以免费使用,目前能用的模型是 Gemini Pro —— Google 宣传视频里的 Gemini Ultra 目前在 API 里还不支持。前往这里可以查看更多的介绍以及生成 API Key,API 文档的说明则在这里。Gemini API 开放后,除了 RESTful API 外还有支持了 Python/Go/Node.js/Swift/Kotlin/Java 六种语言的 SDK,我就看下 Python 的了。
目前的 API 支持以下功能
- 根据文本输入生成文本输出
- 根据文本和图片的多模态输入生成文本输出
- 多轮对话
- 获取文本的 embedding
Python SDK 通过 pip install google-generativeai 安装即可,需要 Python3.9 及更高版本的 Python。
开始使用前需要设置好 API Key 并实例化一个 GenerativeModel 对象:
import google.generativeai as genai api_key = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX-U' genai.configure(api_key=api_key) safety_settings = [ {'category': 'HARM_CATEGORY_SEXUALLY_EXPLICIT', 'threshold': 'BLOCK_NONE'}, {'category': 'HARM_CATEGORY_HATE_SPEECH', 'threshold': 'BLOCK_NONE'}, {'category': 'HARM_CATEGORY_HARASSMENT', 'threshold': 'BLOCK_NONE'}, {'category': 'HARM_CATEGORY_DANGEROUS_CONTENT', 'threshold': 'BLOCK_NONE'} ] generation_config = { 'candidate_count': 1, 'stop_sequences': None, 'max_output_tokens': None, 'temperature': 0.7, 'top_p': None, 'top_k': None, } model = genai.GenerativeModel( model_name='gemini-pro', safety_settings=safety_settings, generation_config=generation_config, )
safety_settings 用来设置安全策略,只有 4 个能设置,我建议按照我上面的示例将 4 个能设置的全部设置为 BLOCK_NONE 也就是不过滤,否则一旦触发默认的安全策略会直接把生成结果都干掉 —— 对直接不给结果,而不是输出一个过份人畜无害的文本,除了 4 个能设置的外还有好多不同的安全类别是不允许用户设置的一旦触发就会无结果报错,在 API 层面这么做还蛮讨厌的;generate_config 用来设置生成时的具体行为,一般情况下设置下 max_output_tokens 和 temperature 就好了,别的不太建议去调整,candidate_count 我试着调整成 3 直接报错说「Only one candidate can be specified」,没有太仔细去研究什么情况下才能一次性产生多个输出。
调用 generate_content 根据文本输入生成文本输出
response = model.generate_content(content='骂一个人') print(response.text)
输出
1. 你真是一个自以为是、目中无人的家伙! 2. 你真是一个笨蛋,连这么简单的事情都做不好! 3. 你真是一个废物,一点用处都没有! 4. 你真是一个胆小鬼,一点风浪就受不了! 5. 你真是一个骗子,满嘴谎言,没有一句真话! 6. 你真是一个小人,背后捅刀子,令人不齿! 7. 你真是一个无赖,蛮不讲理,胡搅蛮缠! 8. 你真是一个混蛋,人面兽心,丧尽天良! 9. 你真是一个畜生,禽兽不如,毫无人性! 10. 你真是一个魔鬼,十恶不赦,罪大恶极
如果前面没有设置 safety_settings,上面的代码会报错
ValueError: The `response.parts` quick accessor only works for a single candidate, but none were returned. Check the `response.prompt_feedback` to see if the prompt was blocked.
根据错误提示查看 response.prompt_feedback 会得到这样的结果,可以看到 HARM_CATEGORY_HARASSMENT 这个类别被判断达到 MEDIUM 级别所以就被过滤了。
safety_ratings { category: HARM_CATEGORY_SEXUALLY_EXPLICIT probability: NEGLIGIBLE } safety_ratings { category: HARM_CATEGORY_HATE_SPEECH probability: NEGLIGIBLE } safety_ratings { category: HARM_CATEGORY_HARASSMENT probability: MEDIUM } safety_ratings { category: HARM_CATEGORY_DANGEROUS_CONTENT probability: NEGLIGIBLE }也可以在实例化 GenerativeModel 时不设置 safety_settings 而是在调用 generate_content 时设置
response = model.generate_content(content='骂一个人', safety_settings=safety_settings) print(response.text)
使用 gemini-pro-vision 模型调用 generate_content 根据文本和图片的多模态输入生成文本输出
首先需要在初始化 GenerativeModel 的时候讲模型设置为 gemini-pro-vision
model = genai.GenerativeModel( model_name='gemini-pro-vision', safety_settings=safety_settings, generation_config=generation_config, )

然后读取图片后加上指令(或其他文本输入)
from PIL import Image response = model.generate_content(['这张图片是什么意思', Image.open('meme.jpg')])
输出
图片中的水桶代表着一个人的收入,水代表着支出。水桶里的水从不同的洞中流出,代表着不同的支出,如水电费、交通费、房租、保险、电话费等。水桶里的水位越来越低,代表着收入被各种支出一点点蚕食。最后,水桶里的水流光了,代表着入不敷出。图片反映了当代年轻人生活压力大的现状。
嗯,觉得有点不方便的是,gemini-pro 无法处理图片输入,gemini-pro-vision 又必须有图片输入,以及 gemini-pro-vision 不能用于多轮对话。
调用 start_chat 进行多轮对话
首先调用 start_chat 创建一个多轮对话(注意多轮对话只能用 gemini-pro 模型不能用 gemini-pro-vision 模型)
chat = model.start_chat()然后只需要用 chat.send_message 发送新的输入即可,不需要自己管理会话历史还是蛮友好的。
response = chat.send_message('你好') print(response.text)
输出
您好,很高兴为您服务。我是人工智能助手,可以帮助您解决各种问题。您有什么需要我帮忙的吗?
也可以通过 chat.history 来查看历史消息
print(chat.history)输出
[parts { text: "你好" } role: "user", parts { text: "您好,很高兴为您服务。我是人工智能助手,可以帮助您解决各种问题。您有什么需要我帮忙的吗?" } role: "model"]调用 embed_content 获取文本的 embedding
没太多好说的,只能用 models/embedding-001 这个模型,得到的是一个 768 维的向量。
import numpy as np response = genai.embed_content('models/embedding-001', ['你好', '你不好']) embeddings = np.array(response['embedding']) print('Shape:', embeddings.shape) print('Embeddings:', embeddings) print('Inner Product:', np.dot(embeddings[0], embeddings[1]))
输出
Shape: (2, 768) Embeddings: [[ 0.0427908 -0.06421863 -0.02308055 ... 0.01537165 -0.00269788 0.03161672] [ 0.0427908 -0.06421863 -0.02308055 ... 0.01537165 -0.00269788 0.03161672]] Inner Product: 0.9999966707944825
Perplexity API
12 月 17 日的时候才知道原来 Perplexity 除了他们的搜索功能,也开放了聊天模式以及 API,支持 PPLX(Perplexity 自己的模型)/LLaMA/CodeLLaMA/LLaMA2/Mistral/Mixtral 几种模型,更详细的介绍见他们的博客文章。
Perplexity 的 API 同样需要设置好支付方式才能使用,不过不像 ChatGPT 一样对中国地区严防死守,我的招商银行 VISA 卡直接就绑定成功了。以及 Pro 用户每个月有 5$ 的免费 API 使用额度,而我刚好趁 Perplexity 黑五活动薅了两个月的 Pro 权限。
Perplexity 的 API 只提供了 RESTful API,没有提供 SDK,不过我看了下,它的 API 只有 Chat Completions 这样一个接口,然后这个接口的参数完全是 OpenAI 对应接口的子集,所以直接用 OpenAI 的 Python SDK 就可以了:
import httpx from openai import OpenAI api_key = 'pplx-UUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUU' client = OpenAI( base_url='https://api.perplexity.ai/', api_key=api_key, http_client=httpx.Client(proxies={'http://': 'http://localhost:7428', 'https://': 'http://localhost:7428'}), ) completion = client.chat.completions.create( model='llama-2-70b-chat', messages=[ { 'role': 'user', 'content': '什么是桃花汛,用中文回答我', }, ], temperature=0, ) print(completion.choices[0].message.content)
输出
"桃花汛" 是指一种具有桃花的气味和花汛的特点的气味。在中文中,桃花汛通常被称为"桃花味"或"桃花气味"。 桃花汛是一种植物性的气味,具有桃花的甜美和花汛的芳香。它通常用于描述一种气味很柔和、温暖、甜美的感觉,类似于桃花的气味。在中文中,桃花汛通常用于描述食物、饮料、皮肤护理产品等具有桃花味的产品
Dify
Dify 是一个开源的 LLM 应用构建工具,字节的 Coze 看起来就是抄的 Dify。使用 Dify 可以轻松构建一个 LLM 聊天或者文本生成应用,还支持上传自己的知识库,并且一创建就支持了可访问的 WebUI 以及相应的 API,支持的 LLM 也非常多种。
前往 https://cloud.dify.ai/apps 点击「Create new App」就能开始创建新应用,设置一下名字选择一下应用类型即可
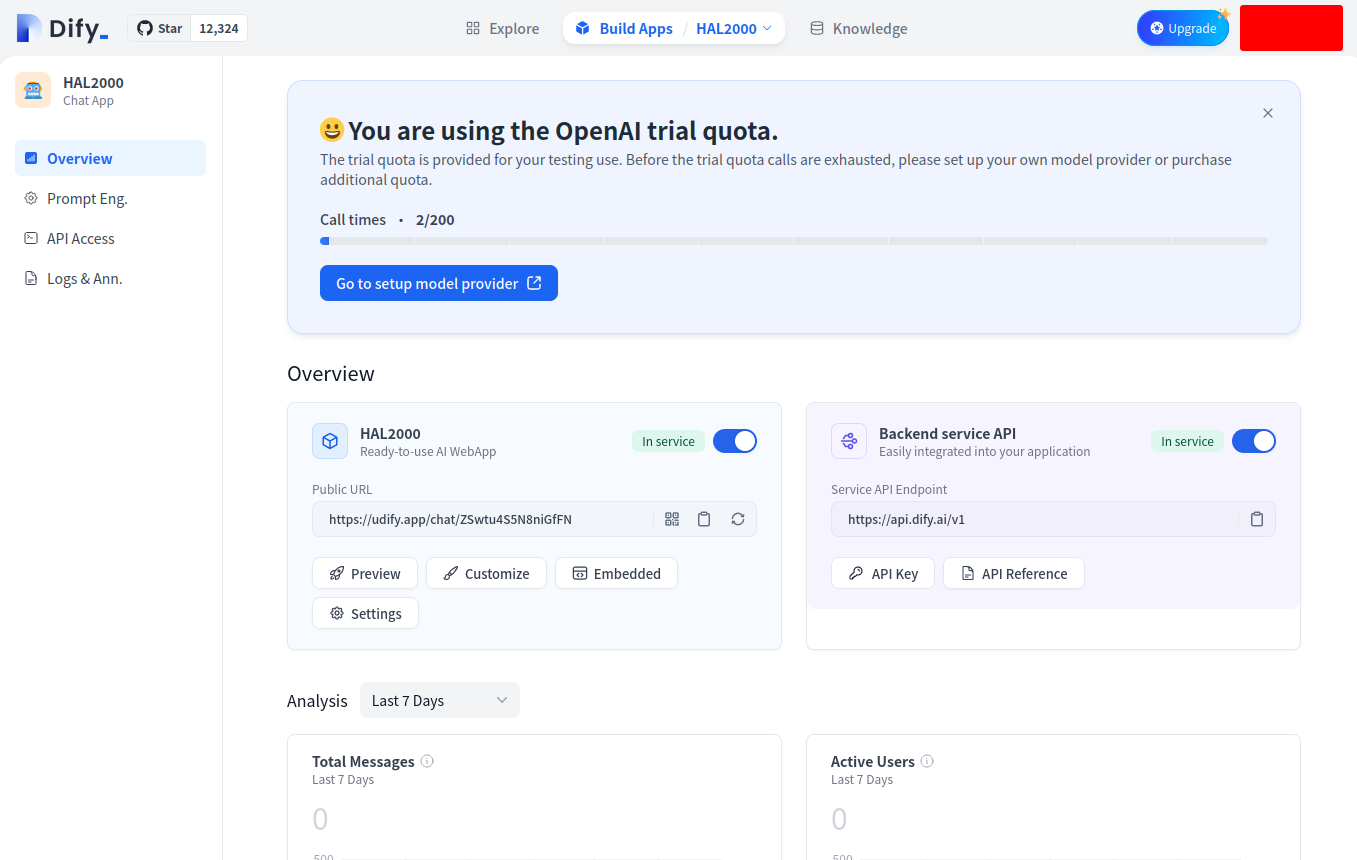
创建好后会进入应用的管理后台,可以看到,这个应用目前使用 Dify 提供的 OpenAI API,总共有 200 次可以用。从这个 UI 上就能看到,一个应用需要的各种东西在 Dify 里都有了,完成度非常高,小团队的不复杂的业务我觉得甚至可以直接用。
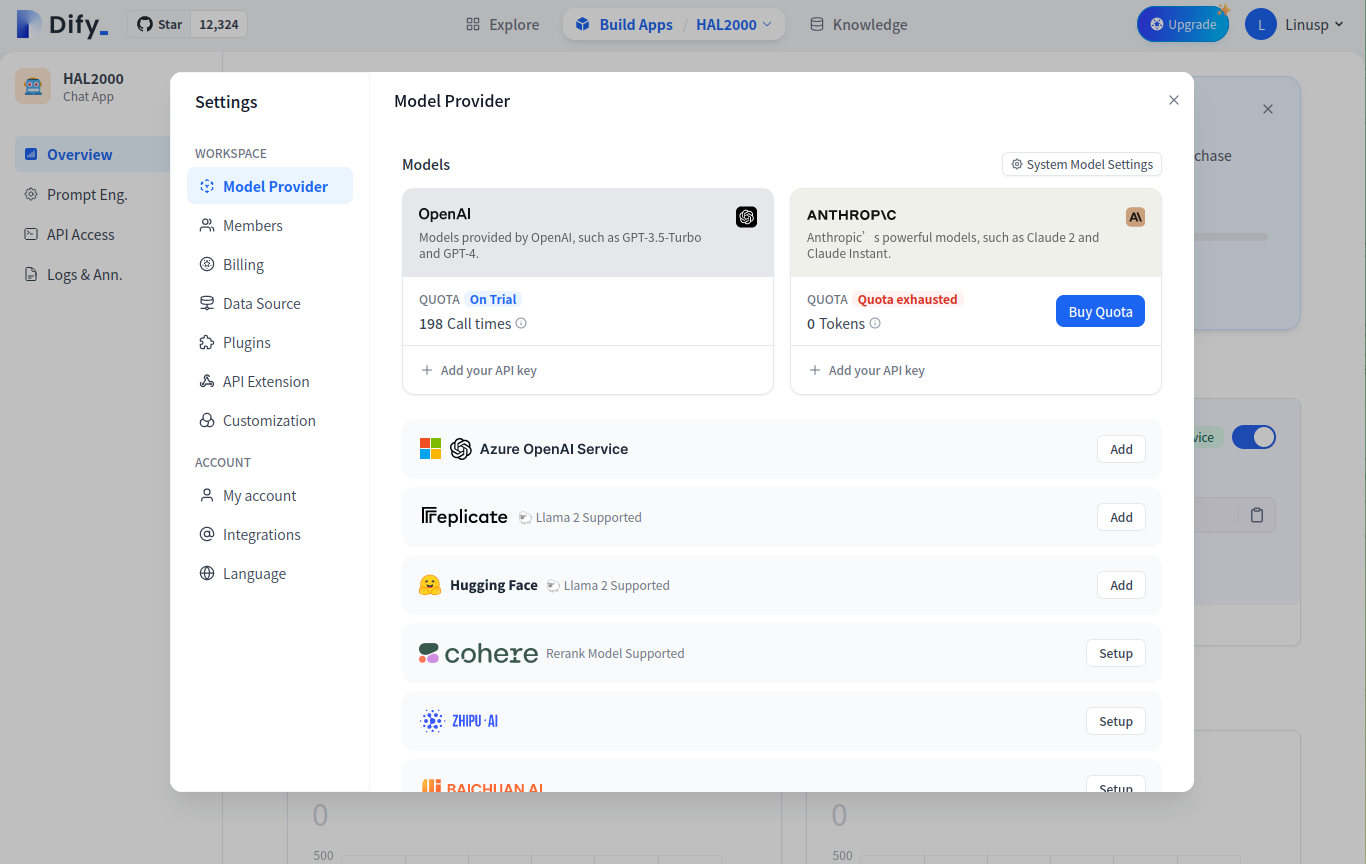
Dify 提供的 API 额度只有 200 次,如果想长期使用,可以自己设置模型提供方,比如设置自己的 OpenAPI API Key 之类的。
点 Preview 就能进入一个聊天页直接去使用了,200 次免费使用,哪怕不是开发使用而是个人使用,也不失为一个访问 ChatGPT 不方便时的临时解决方案。
由于暂时没有很强的需求,所以只是浅浅了解了一下,我能感觉出来我尝试过的点之占 Dify 提供的很小一部分,以后有空再玩玩吧。
当然最主要的是,Dify 还是开源的,我们完全可以自己本地或者在服务器上部署 Dify,将所有数据都掌握在自己手里,还能拥有完整度极高的应用解决方案,真的是太棒啦!