
ZMonster's AI Notes(Alpha) #2:模型汤、推测解码、幻觉的类型与定义、GPT top_logprobs
2024-02-07目录
分享最近关于 AI 方面的笔记、想法以及实践记录。本系列内容模式的最终形态尚不确定,可能会根据个人精力、兴趣及阅读反馈做调整,所以称之为试作版。
从第一期之后拖延了很久,先是花了比较多精力做 2023 年的回顾总结,之后则因为即将过年回家比较焦虑而导致没有办法集中精力,看下过完年后能不能争取专注一些。下一期准备集中了解下幻觉的检测与缓解方法。
术语
简单介绍下我最近新了解到的 AI 领域的一些术语,但不做深入探究。
模型汤(Model Soup)
论文《Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time》 提出的概念,本质上属于模型合并(Model Merging)的一个方法,作者发现把同一个模型在多个不同下游任务上微调过后的权重进行加权平均(论文中尝试了多种方法如直接平均或者学习加权参数)后,能在新的下游任务上也得到效果的提高(相比未微调的基础模型)。其解释我理解是说两个不同的下游任务在微调时会在损失函数的曲面上走不同的下降路线,加权平均后往往能更接近极值点。
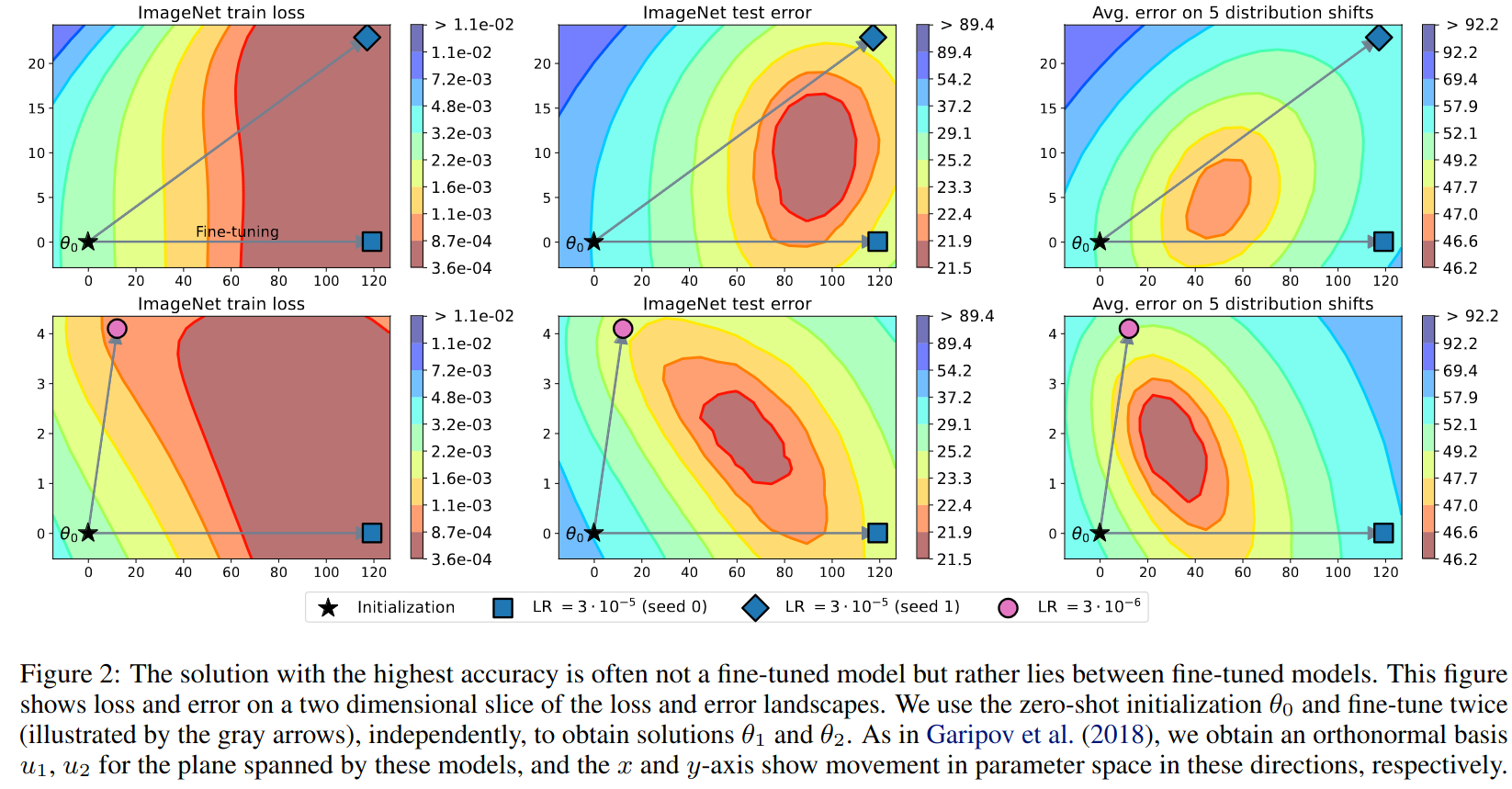
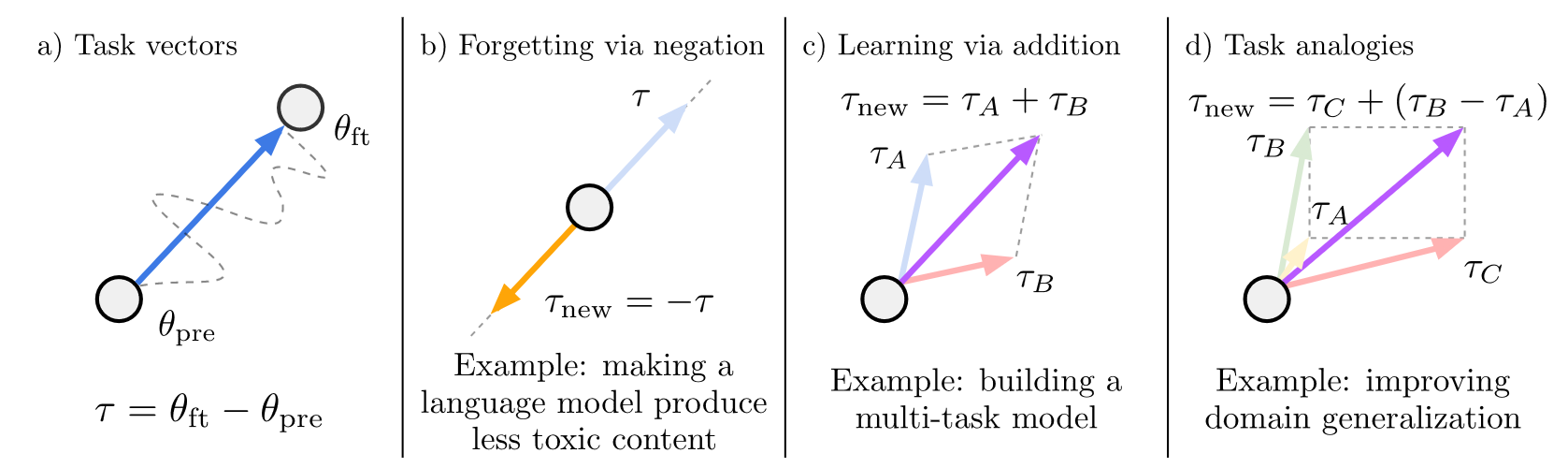
在这个发现的基础上, 《Editing Models with Task Arithmetic》 这篇论文进一步发现微调模型与基础模型之间的权重差(论文中称之为任务向量)具有语义,微调过后的模型可以通过减去这个权重来遗忘这个任务,不同任务的任务向量相加也能获得一个综合了多个任务能力的新模型。
时间错位(Temporal Misalignment)
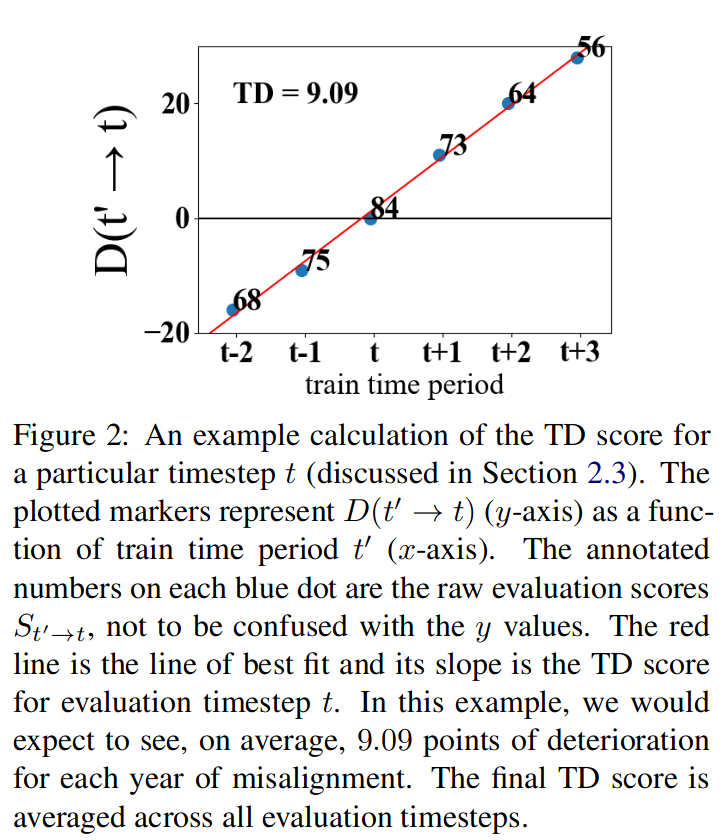
《Time Waits for No One! Analysis and Challenges of Temporal Misalignment》 等一些论文里发现用时间段 A 内训练的大模型在另外的时间段 B 上效果会不好,反映到现实中的大模型表现就是其效果会随时间变化而慢慢在新的文本上效果变差,看起来好像是退化一样 —— 其实不能说是退化,只是人们使用的语言一直在变化,如果要让模型始终保持稳定的表现就需要持续地使用新的数据去进行训练微调。
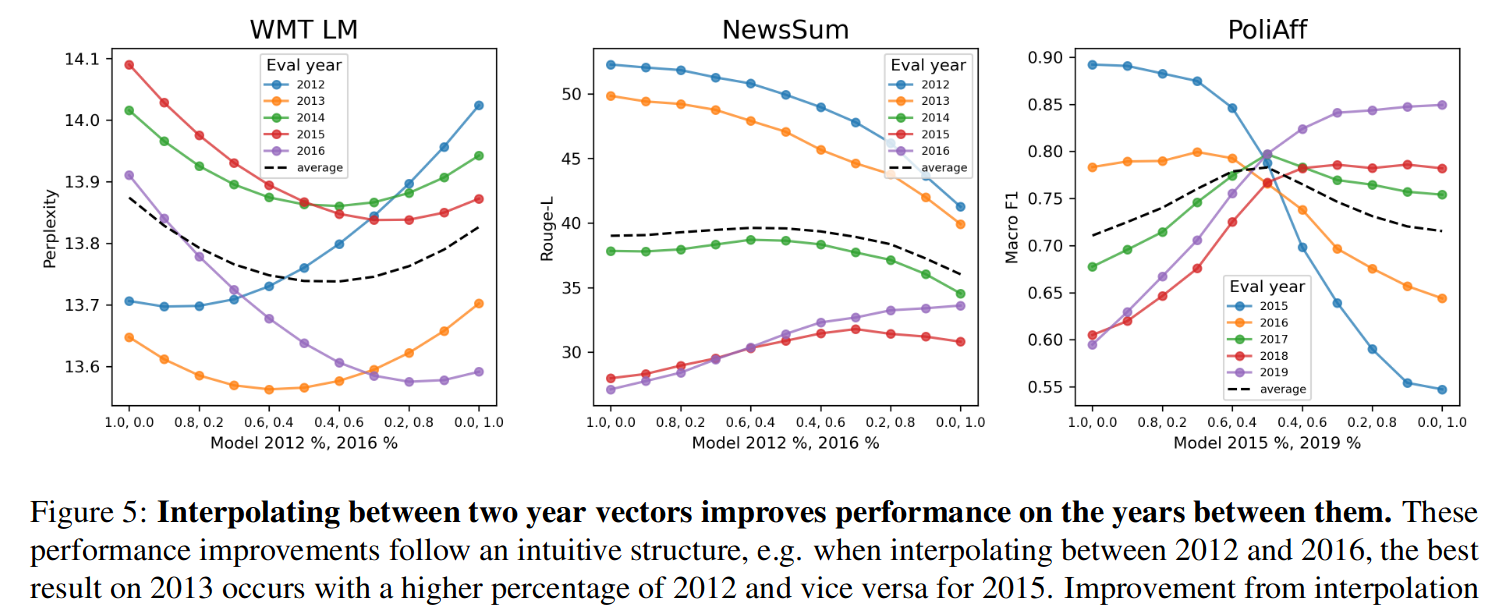
之后 2023 年的论文 《Time is Encoded in the Weights of Finetuned Language Models》 进一步发现,模型的能力在不同年份之间会变差,但相近时间段文本训练的模型效果也会接近,并借鉴前面「模型汤」一节中提到的任务向量的概念,提出了时间向量,发现将两个不同的时间向量进行插值(其实也是加权平均)可以使模型在这两个时间段之间的时间段效果变好,认为可以用不同时间段的文本数据进行微调后得到一个个时间向量然后在有需要的时候混合起来,以低成本地改善任意时间段的模型效果,将这种思路称之为「时间汤」,当然最后也承认这种做法效果还是比不上完整收集所有时间段的数据统一进行训练,不过我个人认为还是很有用的,现在有很多开源的语言模型,借鉴这个思路可以在已有的模型上低成本地进行改进。
推测解码(Speculative Decoding)
Google Research 在论文 《Fast Inference from Transformers via Speculative Decoding》 中提出的一种语言模型生成加速的方法,说是受 CPU 里的分支预测技术的启发,其基本思想是基于模型越大生成每一个 token 时越慢这个状况,引入一个更小更快的草稿模型,让草稿模型来去生成 token 然后让更大的模型去决定是否要接受这个 token,只有草稿模型的生成被认为不够好被拒绝时,才用更大的模型自己去生成 token。按照论文里的不同设置,最高的时候能够以原来不使用草稿模型的生成方法的 6 倍多的速度来完成整个生成过程。

另外 DeepMind 也有一篇论文 《Accelerating Large Language Model Decoding with Speculative Sampling》 讲推测解码的,不过论文里说明了和前面的这篇论文是相同的思路。
论文
写完第一期之后,我选择了幻觉(hallucination)这个主题,决定去梳理清楚这几个问题:
- 目前 LLM 中经常被提的幻觉的定义是什么?
- 幻觉都有哪些类型?
作为一个新兴的概念,幻觉这个术语目前并没有非常一致的共识和清晰的定义,从看到的论文里来看,有一些会尝试先给出相对严格的整体性定义和描述,再仔细区分其中的不同类型,有的则对整体定义一带而过只具体描述了几种类型,另外还有大量在不同子领域分析幻觉现象的工作,其中的幻觉定义和分类就更加繁杂了,我尽量先了解了下任务不相关的幻觉定义及其分类。
Ziwei Ji 的 《Survey of Hallucination in Natural Language Generation》 这篇论文是目前我读到的对幻觉的定义比较通用和清晰的,也是我看的各种幻觉相关的论文里被引用的比较多的,有很多关于幻觉的论文自己不想做定义就直接引用下这篇论文。
这篇论文先从心理学上「幻觉」的定义出发,引用了 Blom 在《A Dictionary of Hallucinations》一书中给的定义:
In the general context outside of NLP, hallucination is a psychological term referring to a particular type of perception. Blom define hallucination as “a percept, experienced by a waking individual, in the absence of an appropriate stimulus from the extracorporeal world”.
这个定义里有几个要点:
- 没有外部刺激
- 但人脑仍产生了类似有外部刺激时的感受
- 并且这种感受可以很真实
借鉴心理学上的定义,Ziwei Ji 给了关于幻觉的定义:
The generated content that is nonsensical or unfaithful to the provided source content.
简单来说,就是模型生成了无意义的文本或者不忠实于指定信息或知识的文本,也就是网络上大家调侃的「一本正经地胡说八道」。此外论文里还有一些幻觉文本的特点的描述,比如说这种文本在表达上一般都很流畅,看起来似乎也是基于某种真实的语境或者背景知识,但往往这种背景知识并不存在或者是错误的。
不过需要注意的是,Ziwei Ji 的定义里有一个「source content」,具体来说:
- 对摘要任务来说,source content 是指待进行总结的文本
- 对翻译任务来说,source content 是指待进行翻译的源语言文本
- 对多轮对话来说,source content 是指对话历史中与当前消息有关的消息
- 对检索式问答来说,source content 是指根据用户输入检索到的问答对语料数据
- 对 data-to-text 来说,source content 是指给定的结构化数据
- ……
那开放式问答这种没有提供上下文的情况,所谓 source content 应该指什么呢?论文里为了保持一个统一的定义,就说这个时候的 source content 应当是世界知识(world knowledge),不过所谓的世界知识又怎么定义就没再提了,虽然看起来是将问题转移了,但比起其他一些论文里不加说明就使用某些假设的做法来说已经好很多了。
在关于幻觉的文献里,经常会在提到幻觉时一起提到忠实性(faithfullness)和事实性(factualness)这两个词,不同论文对这三个概念的使用其实还挺混乱的,Ziwei Ji 也在论文里对这三个概念做了阐释和区分(这也是我喜欢这篇论文的原因,别的很多论文都是一副理所当然的样子把这三个词拿出来用)。在 Ziwei Ji 看来,忠实性是说当我们给定一些信息或知识(注意,用户有可能有意或无意给一些错误的知识)时模型是否能在生成结果时与其保持一致,而事实性则是能否与现实中的事实保持一致,而一些关于幻觉的论文粗暴地将提供给模型的信息或知识当作「事实」(或者说用 fact 这个词来描述给定的信息)就造成了忠实性和事实性两个概念的混淆,而 Ziwei Ji 的做法就是用「世界知识」这个词来代替「事实」以避免混淆,将「世界知识」也作为一个 source content,这样也获得了一个统一的定义。虽然看起来有点文字游戏,但明确地划定词语的界限是很有必要的。
在上述定义的基础上,Ziwei Ji 给出了两个幻觉的子类型定义,分别是:
- 内在幻觉(Intrinsic Hallucinations):指生成的文本与 source content 矛盾、不一致,比如说做摘要明明原文说了「The first vaccine for Ebola was approved by the FDA in 2019」但生成的摘要里却说「The first Ebola vaccine was approved in 2021」
- 外在幻觉(Extrinsic Hallucinations):指生成了与 source content 无关的内容,用给定的 source content 无法验证它是对的还是错的,比如说做翻译的时候,原文是「迈克周四去书店」,按理说应该翻译成「Michael went to the bookstore on Thursday」,结果得到的结果是「Michael happily went to the bookstore with his friend」,这个「happily」和「with his friend」就是外在幻觉 —— 当然,从翻译任务上来说我们当然可以说它是错的,但前面说的「用给定的 source content 无法判断它是对的还是错的」是考虑任务无关的情况的
这个分类和其他一些论文里将幻觉分为忠实性幻觉和事实性幻觉是不一样的,在 Ziwei Ji 这个分类里,内在幻觉有些是忠实性的(当为翻译、摘要等任务时)有些是事实性的(当为开放问答即 source content 是世界知识时),而外在幻觉是指多出来一些无关的内容(当然这个无关具体如何定义和评估又是一个值得讨论的问题),这些内容未必是事实错误的甚至未必是一种错误。有些论文里将幻觉和错误混为一谈在读的时候也让人感到混乱,如果将所有错误都称之为幻觉,那这个新的词也就没有必要存在了。
之后,Yue Zhang 等人在论文 《Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models》 中使用了 Ziwei Ji 对幻觉的定义,并在 Ziwei Ji 的分类基础上基于自己的认识将幻觉分成了三类:
- 输入冲突幻觉(Input-Conflicting Hallucination):和 Ziwei Ji 的内在幻觉的定义基本是一样的
- 上下文冲突幻觉(Context-Conflicting Hallucination):指模型在生成长文本或多次生成时的前后不一致,比如说在生成一个小故事的时候先在开头生成了「小明今年15岁」然后到结尾的时候又生成了「13岁的小明表示看不懂但大受震撼」,从模型运作的方式上来说,前面生成的内容其实也在后面生成的时候充当输入角色了,算是对内在幻觉的一个扩展吧
- 事实冲突幻觉(Fact-Conflicting Hallucination):即生成的内容与世界知识、现实中的事实不相符的情况
Yue Zhang 引用了 Ziwei Ji 对幻觉的定义,但他又直接忽略了外在幻觉这个类型,三个分类其实都可以算在 Ziwei Ji 的内在幻觉这个类型下面,这个也可以理解,毕竟外在幻觉的情况其实有些模糊,在实际操作中并不是特别好进行界定。
然后,Hongbin Ye 等人的论文 《Cognitive Mirage: A Review of Hallucinations in Large Language Models》 也引用了 Ziwei Ji 的定义,但没有像 Yue Zhang 一样尝试去做幻觉的类型划分,而是收集了各个具体任务中的幻觉定义和类型划分的工作,如果想要了解特定任务而非任务无关的幻觉的定义和分类,这篇论文是一个非常不错的入口。限于个人精力我暂时没有去对里面罗列的各种其他论文去做了解,等有需要了再说吧。
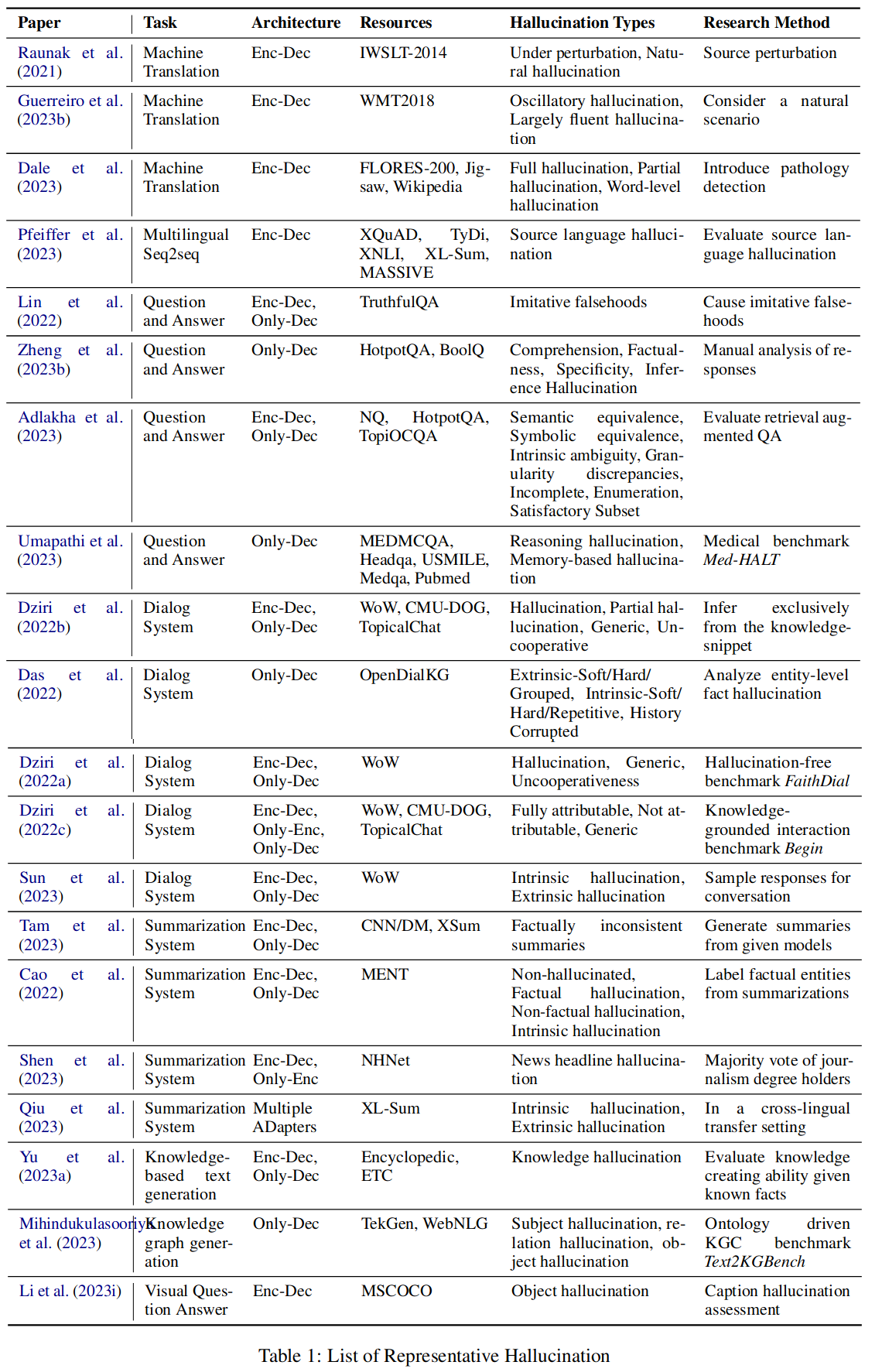
接着,Lei Huang 等人的综述性论文 《A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions》 也基于 Ziwei Ji 的定义给出了自己的二级幻觉分类:
- 事实性幻觉
- 事实不一致(Factual Inconsistency):指生成结果里有与已知事实不一致的的错误生成结果,认为这个是最常见的
- 事实编造(Factual Fabrication):指生成结果里一些陈述,这些陈述用已知的事实无法验证、或者说已知的事实 —— 话说回来,编造的事实能称之为「事实」么,这种用词就让人觉得比较混乱
- 忠实性幻觉
- 指令不一致(Instruction Inconsistency):指模型没有遵循用户的任务指令去做了别的事情,比如让翻译结果因为待翻译的内容是一个问句就去回答这个问句了
- 上下文不一致(Context Inconsistency):指生成结果单纯和输入中的内容不一致的情况,和 intrinsic hallucination、input-conflicting hallucination 是一个意思,但用的是 context 这个词……
- 逻辑不一致(Logical Inconsistency):指在做逻辑推理时,生成的推理步骤之间不一致或者推理步骤和最终结果不一致的情况,可以算作 Yue Zhang 分类里上下文冲突幻觉的一个特例
Lei Huang 的分类我是觉得有点问题的:首先指令不一致有专门的工作即指令追随(Instruction Following),我认为这是一种混淆错误与幻觉的行为,而作者在论文里给出这个分类的理由居然说是考虑现在 LLM 非常以用户为中心需要重点考虑和用户保持一致,我觉得不太能说服我;此外,为什么加入逻辑不一致这个分类,也没做什么解释,大概也是认为逻辑推理能力现在研究比较热门?如果是一篇专门讲逻辑推理中幻觉问题的论文,我觉得没什么问题,但这篇论文又标榜自己是个综述,就感觉这样做不太合适。
除了上述基本都基于 Ziwei Ji 给的定义来进行定义扩充或分类细化的工作外,也有一些明确提出定义标准的,目前我看到说得比较清楚的是 Ayush Agrawal 等人在其论文 《Do Language Models Know When They're Hallucinating References?》 所给出的定义:
We define hallucination to be fabricated text, meaning text that is not grounded in this training set. In contrast, correctness is evaluated with respect to ground-truth answers.
也就是说,在 Ayush Agrawal 的定义里,所谓的幻觉是指生成结果中无法在训练数据中找到依据的杜撰文本。这个定义就把「事实性」「正确性」这些特别宽泛模糊很难界定的概念完全排除出去了,作者也明确说认为幻觉未必就是事实上不正确的,比如说训练数据里提到说人脑只开发了 10% 虽然它是错误的,但基于这样的训练数据训练出来的模型如果生成了相关的文本,那么就不能称之为为幻觉,并认为现在很多讨论幻觉的工作把 groundedness (不知道该怎么翻译,在这篇论文里的语境里就是指在训练数据中存在相关的文本这个意思)和 correctness 也就是正确性混为一谈。
Much work on hallucination conflates groundedness and accuracy, often equating hallucination with fallacy and evaluating hallucinations using accuracy on fact-based assessments, without regard to the training data. We adopt the groundedness definition of hallucination even though it may often be less clear-cut and more difficult to evaluate than factuality.
这个定义相比 Ziwei Ji 的定义做了非常强但也很明确的约束,可能未必符合大众的认知和期望,但我还蛮喜欢这个定义的,清晰明确便于进行评估。
实践
GPT API 中的 top_logprobs 参数
在之前,OpenAI GPT 的 LLM API 分为 Completions 和 Chat 两个,其中 Completions 接口能使用 text-davinci-003 等更旧的 GPT-3 模型,而 Chat 接口则可以使用 gpt-3.5-turbo 和 gpt-4 等更新的模型,但我一直都很喜欢 Completions 接口,因为这个旧的接口提供一个 logprobs 参数,可以输出模型给每个 token 的概率,甚至还能输出每一个 token 时的 topn 的其他 token 及概率,这就使得我可以利用它来计算给定 prompt 或者输出的困惑度(perplexity) ,用来做简单的效果评估,或者也可以通过每一步输出的 topn 结果进行组合在一次调用里生成多个结果(对输出非步骤性列表比如说帮忙起名字的任务来说很有用的),In-Context Learning 里一些用来判断模型是否存在 bias (比如说做情感分类的时候发现给定一个空输入的时候也会倾向于预测为 positive)并基于这个 bias 的偏离概率去做校准的工作也需要能得到每个 token 的概率……但长期以来能使用更新更好模型的 Chat 接口都没有支持这个参数,也不知道 OpenAI 在干什么。
这几天去翻了下 API 说明发现 Chat 接口已经支持输出每个 token 的概率以及 topn 的 token 及概率了,看了下 Changelog 是在 2023-12-15 的更新里加上的,不过和旧的 Completions 接口有一点区别:
- logprobs 参数用来设置是否要返回 token 的概率
- top_logprobs 参数则用来设置要返回最好的几个 token 及其概率,最大值是 5
不过美中不足的是,原先 Completions 接口还有个 echo 参数当设置为 true 的时候会在输出结果里带上输入 —— 不是说将输入的内容重新生成了一遍,只是将输入内容附加到输出内容前面,有了这个参数才能获得输入中每个 token 的概率用来计算 prompt 的困惑度,但这个参数在 Chat 接口中仍然没有支持。
把之前自己利用 Completions 接口的 logprobs 参数做困惑度计算(如前面所说 Chat 接口只能计算生成结果的困惑度无法计算 prompt 的困惑度)和多个结果生成的脚本改了下,放到 gists 了,这里就不展示代码了,只来展示一下运行效果。
获得生成结果的困惑度
python playgpt.py --model gpt-3.5-turbo \ --proxy 'http://localhost:8888' \ --max-tokens 128 \ --temperature 0 \ --prompt '桃花汛是什么?'
得到的结果是:
PROMPT: 桃花汛是什么? RESULT: 桃花汛是指中国古代文学中的一个典故,也是指桃花开放时期的洪水。根据传说,每年春天桃花盛开时,河水会因为桃花的美丽而上涨,形成洪水。这种洪水被称为桃花汛。桃花汛在文学作品中常常被用来比喻美好的事物或者美 CANDIDATE RESULTS(With PPL): TEXT: '桃花汛是指中国古代文学中的一个典故,也是指桃花开放时期的洪水。根据传说,每年春天桃花盛开时,河水会因为桃花的美丽而上涨,形成洪水。这种洪水被称为桃花汛。桃花汛在文学作品中常常被用来比喻美好的事物或者美', PPL: 1.386107427324887 Usage: prompt_tokens: 18 completion_tokens: 128 total_tokens: 146temperature 参数不为 0 时,模型输出的结果在未必会在 top_logprobs 结果里输出 —— 这也可以理解,毕竟当 temperature 大于 0 时将会进行概率采样,是有可能选中 topn 之外的 token 的,所以我写的这个示例,只有在 temperature 设置为 0 时才可以稳定获得结果的困惑度,如果设置不为 0 有时候是会没有困惑度结果的。
一次生成多个名字
PROMPT: 起一个女性名字,姓刘,名字要和月亮有关,但不要直接用月字,尝试根据一些古诗词里的典故,使用较常见而不是冷僻的字,只输出名字无需其他。结果是:刘
python playgpt.py --model gpt-3.5-turbo \ --proxy 'http://localhost:8888' \ --max-tokens 10 \ --top-logprobs 3 \ --result-num 10 \ --temperature 0 \ --prompt '起一个女性名字,姓刘,名字要和月亮有关,但不要直接用月字,尝试根据一些古诗词里的典故,使用较常见而不是冷僻的字,只输出名字无需其他。结果是:刘'
得到的结果是
PROMPT: 起一个女性名字,姓刘,名字要和月亮有关,但不要直接用月字,尝试根据一些古诗词里的典故,使用较常见而不是冷僻的字,只输出名字无需其他。结果是:刘 RESULT: 婵娟 CANDIDATE RESULTS(With PPL): TEXT: '婵娟', PPL: 1.3893958134060524 TEXT: '嫵娟', PPL: 1.4518073221689531 TEXT: '娵娟', PPL: 1.753700750011277 TEXT: '婉娟', PPL: 2.1273314013866393 TEXT: '嫉娟', PPL: 2.2228908964694374 TEXT: '娉娟', PPL: 2.6851258929509876 TEXT: '婷娟', PPL: 3.300551957606001 TEXT: '嫷娟', PPL: 3.4488123924201473 TEXT: '婵婟', PPL: 3.5588571357287666 TEXT: '嫵婟', PPL: 3.718720611038904 Usage: prompt_tokens: 87 completion_tokens: 6 total_tokens: 93生成效果先不说,可以看到,Usage 里 prompt_tokens 是 87、completion_tokens 是 6,相比其他方法来生成多个名字能减少一些 token 使用,比如说:
- 最粗暴的方法是设置 temperature 大于 0 然后反复运行 10 次,假设每次的 completion_tokens 都是 6,那么 10 次需要消耗 930 个 token
- 更好一点的方法是在 prompt 里要求输出多个名字,假设 prompt 不变,completion_tokens 至少要是 60,那么至少要消耗 153 个 token